Skip that intro! - Matching audio segments in multiple files
If you ever binge-watched a series you should already be familiar with the urge to skip ASAP that intro/outro song.
Many streaming services already have a skip intro button, but how does it work? Did you think that the content partners need to specify timestamps for intro/outros at the content ingest stage? That would be too easy.
I attempted to automate the intro detection with chromaprint mostly for fun because it seems that was my definition of fun at the time.
First thing, install the workhorse of the industry ffmpeg to do some work on the video files themselves and golang wrappers for chromaprint
Preparation phase
Let’s say I got hold of some JoJo’s Bizarre Adventure episodes.
First, I need to strip the audio from the video files, using ffmpeg is fast and it looks like this in my case.
Strip the audio stream: ffmpeg -i input.mkv -vn -c:a copy output.m4a
Next, I’ll need to uncompress it into a .wav file also drop as many bytes as possible, making it mono and trimming it to first 3 minutes where usually the intro song plays should be good enough.
Convert to .wav: ffmpeg -i output.m4a output.wav
Convert stereo .wav to mono .wav: ffmpeg -I output.wav -ac 1 m_output.wav
Trim down to 180 seconds: ffmpeg -i m_output.wav -af atrim=0:180 m_t_output.wav
Yes, it can be automated with a bash script, but I needed to do for like ten files… I should’ve written a script.
Finding the common region
By running a piece of raw audio data (a .wav file with no header) through chromaprint you get the fingerprints of those files which are actually just spectrograms, more info on how it works.

Typical output for a 3min .wav file
Comparing two perfectly aligned audio files results in this image.
The black area at the beginning is where the spectrograms XOR-ed perfectly resulting mostly in a black area.

Comparing first 2min of two episodes
But in some cases, most of the cases actually intros aren’t aligned perfectly, before the intro song begins there could be some scenes from previous episodes or some pre-intro scenes from the current episode. Those scenes always vary in length and if I were to compare the spectrograms it would look like a bunch of noise.
One way to find the common areas on two different spectrograms is to slide them past each other like a puzzle each iteration resulting in a match score. I start with an 50% offset between the slices (golang view of an array) and end on -50% offset, good enough for the intro I’m searching, each time the offset decreases the slices get actually a bit bigger then again smaller (highlighted in blue). Another way could be using the “Longest Common Substring” approach with some tolerance between values but that’s for another time.
After all the slide and compare action, I’ll pick the iteration with the best score and do a comparison, usually resulting in something like the picture above.

Initial state - incremental sliding and comparing two fingerprints
By the way, raw fingerprints of those two files are just int32 slices, images above are just for visual aid and the int32 values are one-pixel width vertical slices from each fingerprint.
The comparison between the values is done using Hamming distance for each pair of int32 values.
Once I compared the best match I get a similar result but with more numbers:
[15, 20, 9, 13, 12, 10, 6, 7, 3, 2, 2, 1, 0, 3, 2, 1, 9, 13, 12, 14]
Each value is the Hamming distance between two int32 pairs and its easy to spot somewhere in the middle there is a subsequence that gets below 10 and sits there for quite a while.
That is the matching area I was looking for, If I were to compare those fingerprints and output an image it would have a blacker area somewhere in the middle, next step is to calculate how long it is, then taking into account the offset it is trivial to calculate where the intro song started and ended for both files.
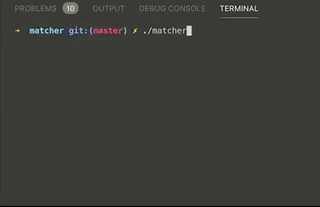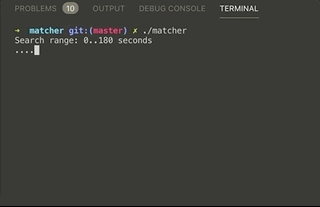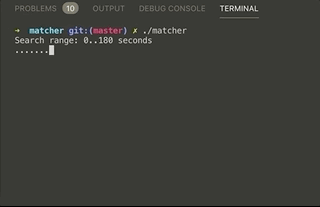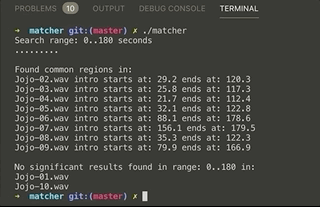
Searching for intro in 10 files (single threaded)
Conclusion
The result is a robust way to find common regions/fingerprints in two or more audio files, at least in this concrete use case.
The implementation can be seen here.
Disclaimer: The solution is in no way perfect, probably not written in an idiomatic golang style since it was one of the first golang projects that was actually of any use.